マルチテナンシー
このページでは、クラスターのマルチテナンシーに利用可能な設定オプションとベストプラクティスの概要について説明します。
クラスターを共有することで、コストを削減し、管理を簡素化することができます。 しかし、クラスターの共有には、セキュリティ、公平性、ノイジーネイバー(noisy neighbor)の管理といった課題も伴います。
クラスターは多様な方法で共有できます。 場合によっては、異なるアプリケーションが同じクラスター内で実行されることがあります。 別の場合では、同じアプリケーションの複数のインスタンスが同じクラスター内で実行され、それぞれが異なるエンドユーザー向けに提供されることもあります。 こうしたクラスター共有の方法は、総称して マルチテナンシー という用語で説明されることが多いです。
Kubernetesには、エンドユーザーやテナントという第一級の概念はありませんが、さまざまなテナンシー要件の管理に役立つ機能がいくつか用意されています。 これらについて、以下で説明します。
ユースケース
クラスターの共有方法を決定する最初のステップは、ユースケースを理解することです。 これにより、利用可能なパターンやツールを評価できます。 一般的に、Kubernetesクラスターにおけるマルチテナンシーは、大きく2つのカテゴリーに分類されますが、多くのバリエーションやハイブリッド形式も存在します。
複数チーム
マルチテナンシーの一般的な形態は、組織内の複数のチーム間でクラスターを共有することです。 各チームは1つ以上のワークロードを運用することがあります。 これらのワークロードは、互いに通信したり、同じクラスターまたは異なるクラスター上にある他のワークロードと通信したりする必要があることが多いです。
このシナリオでは、チームのメンバーは、kubectlなどのツールを介してKubernetesリソースに直接アクセスするか、GitOpsコントローラーやその他のタイプのリリース自動化ツールを介して間接的にアクセスすることがよくあります。
異なるチームのメンバー間には、ある程度の信頼関係が存在することが多いですが、RBAC、クォータ、ネットワークポリシーなどのKubernetesポリシーは、クラスターを安全かつ公平に共有するために不可欠です。
複数の顧客
もう1つの主要なマルチテナンシーの形態は、Software-as-a-Service(SaaS)ベンダーが顧客向けにワークロードの複数のインスタンスを実行することです。 このビジネスモデルは、このデプロイメントスタイルと強く関連付けられているため、多くの人がこれを「SaaSテナンシー」と呼んでいます。 しかし、より適切な用語は「マルチカスタマーテナンシー」かもしれません。 なぜなら、SaaSベンダーは他のデプロイメントモデルを使用することもあり、このデプロイメントモデルはSaaS以外でも使用できるためです。
このシナリオでは、顧客はクラスターにアクセスできません。 Kubernetesは顧客の視点からは見えず、ベンダーがワークロードを管理するためにのみ使用されます。 コスト最適化は重要な懸念事項となることが多く、ワークロードを互いに強力に分離するためにKubernetesポリシーが使用されます。
用語
テナント
Kubernetesにおけるマルチテナンシーを議論する際、「テナント」の単一の定義は存在しません。 むしろ、テナントの定義は、マルチチームとマルチカスタマーのどちらのテナンシーについて議論しているかによって異なります。
複数チームで利用する場合、テナントは通常、1つのチームを指します。 各チームは通常、サービスの複雑さに応じてスケールする少数のワークロードをデプロイします。 ただし、「チーム」の定義自体があいまいな場合があります。 というのも、チームは上位レベルの部門に編成されたり、より小さなチームに細分化されたりすることがあるためです。
対照的に、各チームが新しいクライアントごとに専用のワークロードをデプロイする場合、マルチカスタマーモデルのテナンシーを使用しています。 この場合、「テナント」は単に1つのワークロードを共有するユーザーグループです。 これは会社全体のように大きい場合もあれば、その会社内の単一のチームのように小さい場合もあります。
多くの場合、同じ組織が異なるコンテキストで「テナント」の両方の定義を使用することがあります。 たとえば、プラットフォームチームは、セキュリティツールやデータベースなどの共有サービスを複数の内部「顧客」に提供することがあり、SaaSベンダーも開発クラスターを共有する複数のチームを持つことがあります。 また、ハイブリッドアーキテクチャも可能です。 たとえば、SaaSプロバイダーが機密データ用の顧客ごとのワークロードと、マルチテナント共有サービスを組み合わせて使用する場合です。
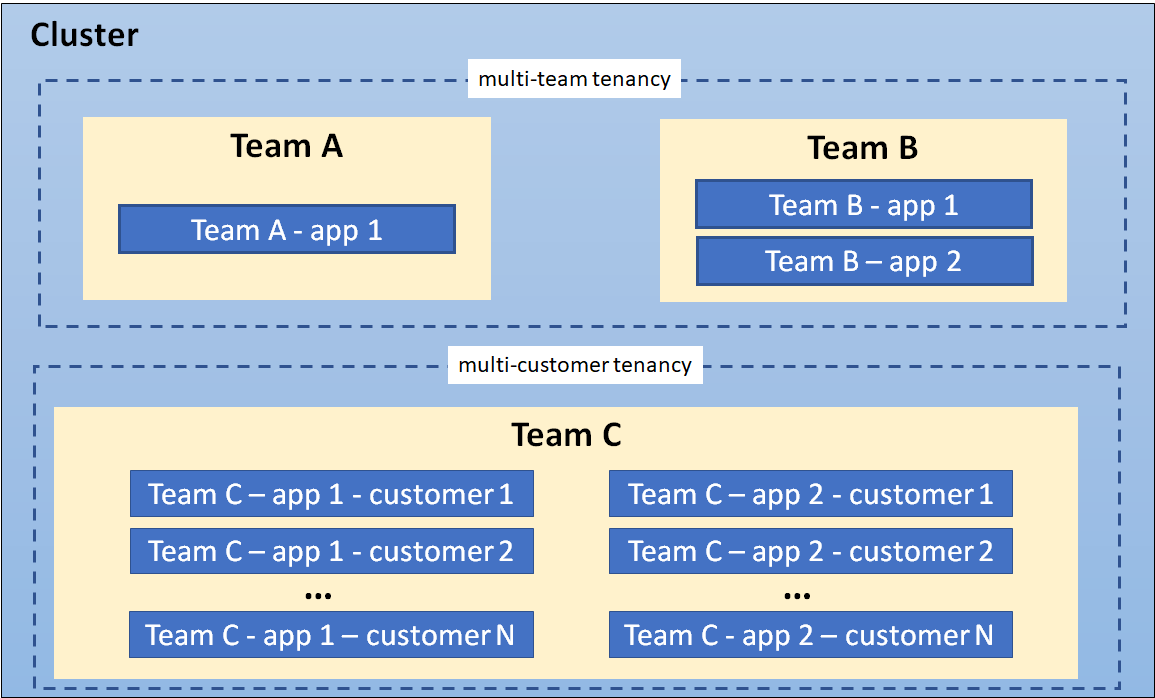
複数のテナンシーモデルが共存するクラスター
分離
Kubernetesには、マルチテナントソリューションを設計および構築するための方法がいくつかあります。 これらの各方法には、分離レベル、実装の労力、運用の複雑さ、サービスのコストに影響を与える独自のトレードオフがあります。
Kubernetesクラスターは、Kubernetesソフトウェアを実行するコントロールプレーンと、テナントワークロードがPodとして実行されるワーカーノードで構成されるデータプレーンから構成されます。 テナントの分離は、組織の要件に基づいて、コントロールプレーンとデータプレーンの両方に適用できます。
提供される分離のレベルは、「ハード」マルチテナンシー(強力な分離を意味する)や「ソフト」マルチテナンシー(より弱い分離を意味する)といった用語で説明されることがあります。 特に、「ハード」マルチテナンシーは、テナントが互いに信頼していないケースを説明するためによく使用されます。 これは、セキュリティやリソース共有の観点から、データの流出やDoSなどの攻撃を防ぐことを含みます。 データプレーンは通常、攻撃対象領域がはるかに大きいため、「ハード」マルチテナンシーではコントロールプレーンの分離も依然として重要ですが、データプレーンの分離には特別な注意が必要です。
しかし、「ハード」と「ソフト」という用語には、すべてのユーザーに適用可能な単一の定義がないため、混乱を招くことがよくあります。 むしろ、「硬さ」や「柔らかさ」は、広範なスペクトラムとして理解する方が適切です。 要件に基づいて、クラスター内でさまざまなタイプの分離を維持するために多様な技術が利用できます。
より極端なケースでは、クラスターレベルの共有を完全に諦め、各テナントに専用のクラスターを割り当てる方が簡単または必要な場合があります。 VMが適切なセキュリティ境界とみなされない場合は、専用のハードウェア上で実行することも考えられます。 これは、クラスターの作成と運用のオーバーヘッドが少なくともある程度クラウドプロバイダーによって負担されるマネージドKubernetesクラスターの場合、より簡単かもしれません。 より強力なテナント分離の利点と、複数のクラスターを管理するコストおよび複雑さを比較検討する必要があります。 Multi-cluster SIGは、これらのタイプのユースケースへの対処を担当しています。
このページの残りの部分では、共有Kubernetesクラスターに使用される分離技術に焦点を当てます。 ただし、専用クラスターを検討している場合でも、これらの推奨事項を確認しておく価値はあります。 ニーズや機能が変化した際に、将来的に共有クラスターへ移行する柔軟性を確保できるためです。
コントロールプレーンの分離
コントロールプレーンを分離することで、異なるテナント間でKubernetes APIリソースへのアクセスや影響を防ぐことができます。
名前空間
Kubernetesでは、名前空間は、単一のクラスター内でAPIリソースのグループを分離するメカニズムを提供します。 この分離には2つの重要な側面があります。
-
名前空間内のオブジェクト名は、他の名前空間内のオブジェクト名と重複しても構いません。 これはフォルダー内のファイルに似ています。 これにより、各テナントは他のテナントが何をしているかを考慮せずに、リソースに名前を付けることができます。
-
多くのKubernetesセキュリティポリシーは、名前空間スコープで適用されます。 たとえば、RBACロールとネットワークポリシーは、名前空間スコープのリソースです。 RBACを使用することで、ユーザーとサービスアカウントを名前空間に制限できます。
マルチテナント環境では、名前空間はテナントのワークロードを論理的かつ明確な管理単位にセグメント化するのに役立ちます。 実際、一般的な慣例は、複数のワークロードが同じテナントによって運用されている場合でも、すべてのワークロードを独自の名前空間に分離することです。 これにより、各ワークロードが独自のアイデンティティを持ち、適切なセキュリティポリシーで設定できるようになります。
名前空間の分離モデルでは、テナントワークロードを適切に分離するために、他のいくつかのKubernetesリソース、ネットワークプラグイン、セキュリティベストプラクティスへの準拠の設定が必要です。 これらの考慮事項については以下で説明します。
アクセス制御
コントロールプレーンにおいて最も重要な分離のタイプは認可です。 チームまたはそのワークロードが互いのAPIリソースにアクセスや変更を行える場合、他のすべてのポリシーを変更または無効化できてしまうため、それらのポリシーによる保護が無効になります。 したがって、各テナントが必要とする名前空間にのみ適切なアクセス権を持ち、それ以上を持たないようにすることが重要です。 これは「最小権限の原則」として知られています。
ロールベースアクセス制御(RBAC)は、Kubernetesコントロールプレーンで、ユーザーとワークロード(サービスアカウント)の両方に対して認可を強制するために一般的に使用されます。 RoleとRoleBindingは、アプリケーション内でアクセス制御を強制するために名前空間レベルで使用されるKubernetesオブジェクトです。 クラスターレベルのオブジェクトへのアクセスを認可するための類似のオブジェクトも存在しますが、マルチテナントクラスターではあまり有用ではありません。
マルチチーム環境では、RBACを使用して、テナントのアクセスを適切な名前空間に制限し、クラスター全体のリソースはクラスター管理者などの特権ユーザーのみがアクセスまたは変更できるようにする必要があります。
ポリシーがユーザーに必要以上の権限を付与している場合、これは影響を受けるリソースを含む名前空間をより細かい名前空間にリファクタリングする必要があることを示す兆候である可能性が高いです。 名前空間管理ツールは、異なる名前空間に共通のRBACポリシーを適用しながら、必要に応じて細かいポリシーを許可することで、これらの細かい名前空間の管理を簡素化できます。
クォータ
Kubernetesワークロードは、CPUやメモリなどのノードリソースを消費します。 マルチテナント環境では、リソースクォータを使用して、テナントワークロードのリソース使用量を管理できます。 複数チームのユースケースで、各テナントがKubernetes APIにアクセスできる場合、リソースクォータを使用して、各テナントが作成できるAPIリソースの数(たとえば、Podの数やConfigMapの数)を制限できます。 オブジェクト数を制限することで公平性を確保し、コントロールプレーンを共有する他のテナントに影響を与える ノイジーネイバー の問題を回避することを目指します。
リソースクォータは名前空間スコープのオブジェクトです。 テナントを名前空間にマッピングすることで、クラスター管理者はクォータを使用して、テナントがクラスターのリソースを独占したり、コントロールプレーンに過剰な負荷をかけたりしないようにできます。 名前空間管理ツールはクォータの管理を簡素化します。 また、Kubernetesクォータは単一の名前空間内でのみ適用されますが、一部の名前空間管理ツールを使用すると、名前空間のグループ間でクォータを共有できます。 これにより、組み込みのクォータよりもはるかに柔軟な運用が可能になり、管理の手間も削減できます。
クォータは、各テナントが割り当てられたリソース量を超えて消費することを防ぎます。 これにより、あるテナントが他のテナントのワークロードのパフォーマンスに悪影響を与える「ノイジーネイバー」の問題を最小限に抑えられます。
名前空間にクォータを適用する場合、Kubernetesでは各コンテナのリソース要求と制限も指定する必要があります。 制限は、コンテナが消費できるリソース量の上限です。 制限を超えるリソースを消費しようとするコンテナは、リソースタイプに基づいて、スロットリングまたは強制終了されます。 リソース要求が制限よりも低く設定されている場合、各コンテナには要求された量が保証されますが、ワークロード間で影響が及ぶ可能性が依然として残ります。
クォータでは、ネットワークトラフィックなど、すべての種類のリソース共有を保護できるわけではありません。 以下で説明するように、ノードの分離は、この問題に対するより良い解決策かもしれません。
データプレーンの分離
データプレーンの分離により、異なるテナントのPodとワークロードが十分に分離されることを保証します。
ネットワークの分離
デフォルトでは、Kubernetesクラスター内のすべてのPodは互いに通信可能で、すべてのネットワークトラフィックは暗号化されていません。 これにより、トラフィックが誤ってまたは悪意を持って意図しない宛先に送信されたり、侵害されたノード上のワークロードによって傍受されたりするセキュリティ脆弱性が発生する可能性があります。
Pod間の通信は、ネットワークポリシーを使用して制御できます。 ネットワークポリシーは、名前空間のラベルまたはIPアドレス範囲を使用してPod間の通信を制限します。 テナント間で厳格なネットワーク分離が必要なマルチテナント環境では、Pod間の通信を拒否するデフォルトポリシーから始め、すべてのPodがDNSサーバーに名前解決のためにクエリできるようにする別のルールを追加することをお勧めします。 このようなデフォルトポリシーを設定した上で、名前空間内の通信を許可する、より寛容なルールを追加できます。 名前空間同士の間でトラフィックを許可する必要がある場合、ネットワークポリシー定義のnamespaceSelectorフィールドに空のラベルセレクター'{}'を使用することは推奨されません。 このスキームは、必要に応じてさらに洗練できます。 これは、単一のコントロールプレーン内のPodにのみ適用されることに注意してください。 異なる仮想コントロールプレーンに属するPodは、Kubernetesネットワーキングを介して互いに通信できません。
名前空間管理ツールにより、デフォルトまたは一般的なネットワークポリシーの作成が簡素化されるかもしれません。 さらに、これらのツールの一部では、クラスター全体で一貫した名前空間のラベルのセットを強制できるため、ポリシーの信頼できる基礎となることが保証されます。
警告:
ネットワークポリシーには、ネットワークポリシーの実装をサポートするCNIプラグインが必要です。 プラグインがない場合、NetworkPolicyリソースは無視されます。より高度なネットワーク分離は、サービスメッシュによって提供される場合があります。 サービスメッシュは、名前空間に加えて、ワークロードアイデンティティに基づくOSIレイヤー7ポリシーを提供します。 これらの高レベルのポリシーにより、名前空間ベースのマルチテナンシーの管理が容易になります。 特に、複数の名前空間が単一のテナント専用である場合に有効です。 また、相互TLSを使用した暗号化を提供していることが多く、侵害されたノードが存在する場合でもデータを保護し、専用クラスターまたは仮想クラスター全体で機能します。 ただし、管理がはるかに複雑になる場合があり、すべてのユーザーに適しているとは限りません。
ストレージの分離
Kubernetesは、ワークロードの永続ストレージとして使用可能な複数のタイプのボリュームを提供しています。 セキュリティとデータ分離の観点から、ボリュームの動的プロビジョニングの使用が推奨され、ノードリソースを使用するボリュームタイプは避けるべきです。
StorageClassを使用すると、クラスター管理者が決定したサービス品質レベル、バックアップポリシー、カスタムポリシーに基づいて、クラスターが提供するストレージのカスタム「クラス」を記述できます。
Podは、PersistentVolumeClaimを使用してストレージを要求できます。 PersistentVolumeClaimは名前空間スコープのリソースであり、ストレージシステムの一部を分離し、共有Kubernetesクラスター内のテナントに専用化できます。 ただし、PersistentVolumeはクラスター全体のリソースであり、ワークロードや名前空間とは独立したライフサイクルを持つことに注意することが重要です。
たとえば、各テナントに個別のStorageClassを設定し、これを使用して分離を強化できます。
StorageClassが共有されている場合、再利用ポリシーをDeleteに設定して、PersistentVolumeが異なる名前空間の間で再利用されないようにする必要があります。
コンテナのサンドボックス化
KubernetesのPodは、ワーカーノード上で実行される1つ以上のコンテナで構成されます。 コンテナはOSレベルの仮想化を利用するため、ハードウェアベースの仮想化を利用する仮想マシンよりも弱い分離境界を提供します。
共有環境では、アプリケーションやシステムレイヤーのパッチが適用されていない脆弱性を攻撃者が悪用することで、コンテナブレイクアウトやリモートコード実行が実現し、ホストリソースへアクセスできるようになる可能性があります。 コンテンツ管理システム(CMS)のような一部のアプリケーションでは、顧客が信頼できないスクリプトやコードをアップロードして実行できる場合があります。 いずれの場合でも、強力な分離機能を用いてワークロードをさらに分離・保護する仕組みが求められます。
サンドボックス化は、共有クラスターで実行されているワークロードを分離する方法を提供します。
通常、各Podを仮想マシンやユーザー空間カーネルなどの個別の実行環境で実行することを含みます。
サンドボックス化は、信頼できないコードの実行時や、悪意のあるワークロードが想定される場合に推奨されることが多いです。
このタイプの分離が必要な理由の一部は、コンテナが共有カーネル上で実行されているプロセスであり、基盤となるホストから/sysや/procのようなファイルシステムをマウントするため、独自のカーネルを持つ仮想マシン上で実行されるアプリケーションよりも安全性が低いためです。
seccomp、AppArmor、SELinuxなどの制御を使用してコンテナのセキュリティを強化できますが、共有クラスターで実行されているすべてのワークロードに普遍的なルールセットを適用することは困難です。
サンドボックス環境でワークロードを実行することで、コンテナエスケープからホストを保護できます。
コンテナエスケープは、攻撃者が脆弱性を悪用してホストシステムと、そのホスト上のすべてのプロセス/ファイルにアクセスする攻撃手法です。
仮想マシンとユーザー空間カーネルは、サンドボックス化への2つの一般的なアプローチです。
ノードの分離
ノードの分離は、各テナントのワークロードを互いに分離するために使用できる別の技術です。 ノードの分離では、一連のノードが特定のテナントからのPodの実行専用とされ、異なるテナントのPodの混在は禁止されます。 この構成では、ノード上で実行されているすべてのPodが単一のテナントに属するため、ノイジーテナントの問題が軽減されます。 ノードの分離により、情報漏洩のリスクはやや低くなります。 攻撃者がコンテナからのエスケープに成功したとしても、そのノード上のコンテナとボリュームにしかアクセスできないためです。
テナントごとにワークロードが異なるノード上で実行されていますが、kubeletと(仮想コントロールプレーンを使用しない限り)APIサービスは依然として共有サービスであることに注意することが重要です。 熟練の攻撃者は、kubeletまたはノード上で実行されている他のPodに割り当てられた権限を使用して、クラスター内を横方向に移動し、他のノードで実行されているテナントのワークロードにアクセスできる可能性があります。 これが大きな懸念事項である場合は、seccomp、AppArmor、SELinuxなどの追加のセキュリティ制御の実装、サンドボックス化されたコンテナの使用、テナントごとの個別クラスターの作成を検討してください。
ノードの分離は、課金の面でサンドボックス化されたコンテナよりも単純です。 Pod単位ではなくノード単位で課金できるためです。 また、互換性やパフォーマンスの問題が少なく、サンドボックス化されたコンテナよりも実装が容易な場合があります。 たとえば、各テナントのノードはtaintで設定でき、対応するtolerationを持つPodのみがそれらのノード上で実行できます。 その後、mutating webhookを使用して、テナントの名前空間にデプロイされたPodにtolerationとノードアフィニティを自動的に追加し、そのテナント専用に指定された特定のノードセットで実行されるようにできます。
ノードの分離は、Podノードセレクターを使用して実装できます。
その他の考慮事項
このセクションでは、マルチテナンシーに関連する他のKubernetesの構成要素とパターンについて説明します。
API Priority and Fairness
API Priority and Fairnessは、クラスター内で実行されている特定のPodに優先順位を割り当てることができるKubernetes機能です。 アプリケーションがKubernetes APIを呼び出すと、APIサーバーはPodに割り当てられた優先順位を評価します。 優先順位の高いPodからの呼び出しは、優先順位の低いPodからの呼び出しよりも先に実行されます。 競合が激しい場合、優先順位の低い呼び出しは、サーバーの負荷が低くなるまでキューに入れられるか、リクエストが拒否されます。
API Priority and Fairnessの使用は、顧客がKubernetes APIとインターフェースするアプリケーション(たとえばコントローラー)を実行できるようにしない限り、SaaS環境では一般的ではありません。
サービス品質(QoS)
SaaSアプリケーションを実行している場合、テナントごとに異なるサービス品質(QoS)ティアのサービスを提供する機能が必要になることがあります。 たとえば、パフォーマンス保証や機能が少ないフリーミアムサービスと、特定のパフォーマンス保証を持つ有料サービスティアがある場合があります。 幸いなことに、共有クラスター内でこれを実現するのに役立つKubernetesの構成要素がいくつかあります。 これには、ネットワークQoS、ストレージクラス、Podの優先度とプリエンプションが含まれます。 これらの仕組みはいずれも、テナントが支払った対価に見合ったサービス品質を提供することを目的としています。 まずは、ネットワークQoSから見ていきましょう。
通常、ノード上のすべてのPodはネットワークインターフェースを共有します。 ネットワークQoSがない場合、一部のPodが他のPodを犠牲にして利用可能な帯域幅の不公平なシェアを消費する可能性があります。 Kubernetes bandwidthプラグインは、ネットワーク用の拡張リソースを作成し、Linuxのtcキューを使用して、Kubernetesリソース構成要素(つまり、要求/制限)を使用してPodにレート制限を適用できるようにします。 ただし、ネットワークプラグインのドキュメントによると、このプラグインは実験的であることに注意し、本番環境で使用する前に十分にテストする必要があります。
ストレージQoSの場合、パフォーマンス特性の異なる複数のストレージクラスやプロファイルを作成する必要があるでしょう。 各ストレージプロファイルは、IO、冗長性、スループットなど、異なるワークロードに最適化された異なるサービスティアに関連付けることができます。 テナントが適切なストレージプロファイルをワークロードに関連付けるために、追加のロジックが必要になる場合があります。
最後に、Podの優先度とプリエンプションがあります。 これにより、Podに優先度の値を割り当てることができます。 Podをスケジューリングする際、スケジューラーは、より高い優先度が割り当てられたPodをスケジュールするのに十分なリソースがない場合、より低い優先度のPodを退避させようとします。 共有クラスターで無料と有料など、テナントが異なるサービスティアを持つユースケースがある場合、この機能を使用して特定のティアに高い優先度を与えることができます。
DNS
Kubernetesクラスターには、すべてのServiceとPodの名前からIPアドレスへの変換を提供するドメインネームシステム(DNS)サービスが含まれています。 デフォルトでは、Kubernetes DNSサービスは、クラスター内のすべての名前空間の間での検索を許可します。
マルチテナント環境でテナントがPodや他のKubernetesリソースにアクセスできる場合や、より強力な分離が必要な場合は、Podが他の名前空間内のサービスを検索できないようにする必要があります。 DNSサービスのセキュリティルールを設定することで、名前空間をまたいだDNS検索を制限することができます。 たとえば、CoreDNS(KubernetesのデフォルトのDNSサービス)は、Kubernetesメタデータを活用して、名前空間内のPodとServiceへのクエリを制限できます。 詳細については、CoreDNSドキュメント内の設定例をご覧ください。
テナントごとの仮想コントロールプレーンモデルが使用される場合、テナントごとにDNSサービスを設定するか、マルチテナントDNSサービスを使用する必要があります。 こちらは、複数のテナントをサポートするCoreDNSのカスタマイズ版の例です。
Operator
Operatorは、アプリケーションを管理するKubernetesコントローラーです。 Operatorは、データベースサービスのようなアプリケーションの複数のインスタンスの管理を簡素化できるため、マルチコンシューマー(SaaS)マルチテナンシーのユースケースにおける一般的な構成要素となっています。
マルチテナント環境で使用されるOperatorは、より厳格なガイドラインのセットに従う必要があります。 具体的には、Operatorは次のことを行う必要があります:
- Operatorがデプロイされている名前空間だけでなく、異なるテナントの名前空間内でリソースの作成をサポートする。
- スケジューリングと公平性を確保するために、Podがリソース要求と制限で設定されていることを確認する。
- ノードの分離やサンドボックス化されたコンテナなどのデータプレーン分離技術のためのPodの設定をサポートする。
実装
マルチテナンシーを実現するために、Kubernetesクラスターを共有する方法は主に2つあります。 名前空間を使用する方法(テナントごとの名前空間)と、コントロールプレーンを仮想化する方法(テナントごとの仮想コントロールプレーン)です。
どちらの場合でも、データプレーンの分離に加えて、API Priority and Fairnessといった追加の考慮事項への対応が推奨されます。
名前空間の分離はKubernetesで十分にサポートされており、リソースコストは無視できるほどで、サービス間通信を許可するなど、テナント同士が適切に対話できるメカニズムを提供しています。 ただし、設定が困難な場合があり、カスタムリソース定義(CRD)、ストレージクラス、Webhookなど、名前空間スコープにできないKubernetesリソースには適用されません。
コントロールプレーンの仮想化により、非名前空間スコープのリソースの分離が可能になりますが、その代償としてリソース使用量が増え、テナント間の共有も難しくなります。 名前空間の分離では不十分だが、専用クラスターの維持コスト(特にオンプレミス)やオーバーヘッドの高さ、リソース共有の欠如のために専用クラスターが望ましくない場合に適した選択肢です。 ただし、仮想化されたコントロールプレーン内でも、名前空間を使用することで利点が得られる可能性があります。
これら2つの選択肢について、以下のセクションでより詳しく説明します。
テナントごとの名前空間
前述のように、専用クラスターまたは仮想化されたコントロールプレーンのいずれかを使用している場合でも、各ワークロードを独自の名前空間に分離することを検討するべきです。 これにより、各ワークロードがConfigMapやSecretなどの独自のリソースにのみアクセスでき、各ワークロード専用のセキュリティポリシーを調整できるようになります。 さらに、すべてのクラスター全体で一意となるように名前空間に名前を付けることがベストプラクティスです(つまり、別々のクラスターにある場合でも一意にします)。 これにより、将来的に専用クラスターと共有クラスター間を切り替えたり、サービスメッシュなどのマルチクラスターツールを使用したりする柔軟性が得られます。
逆に、ワークロードレベルだけでなく、テナントレベルで名前空間を割り当てることにも利点があります。 単一のテナントが所有するすべてのワークロードに適用すべきポリシーが多くあるためです。 ただし、これには独自の問題があります。 第一に、個々のワークロードに対してポリシーをカスタマイズすることが困難または不可能になります。 第二に、名前空間を割り当てるべき「テナンシー」の単一レベルを決定することが困難な場合があります。 たとえば、組織に部門、チーム、サブチームがある場合、どれに名前空間を割り当てるべきでしょうか。
可能性のあるアプローチの1つとして、名前空間を階層に編成し、特定のポリシーとリソースをそれらの間で共有することです。 これには、関連する名前空間の間での名前空間ラベルの管理、名前空間のライフサイクル、委任されたアクセス、共有リソースクォータが含まれる場合があります。 これらの機能は、マルチチームおよびマルチカスタマーの両方のシナリオで有用です。
テナントごとの仮想コントロールプレーン
コントロールプレーン分離のもう1つの形態は、Kubernetes拡張機能を使用して、各テナントにクラスター全体のAPIリソースのセグメンテーションを可能にする仮想コントロールプレーンを提供することです。 データプレーンの分離技術をこのモデルと組み合わせることで、複数のテナント間でワーカーノードを安全に管理できます。
仮想コントロールプレーンベースのマルチテナンシーモデルは、各テナントに専用のコントロールプレーンコンポーネントを提供することで、名前空間ベースのマルチテナンシーを拡張します。 これにより、クラスター全体のリソースとアドオンサービスを完全に制御できるようにします。 ワーカーノードはすべてのテナント間で共有され、通常はテナントがアクセスできないKubernetesクラスターによって管理されます。 このクラスターは、スーパークラスター(または ホストクラスター)と呼ばれることがよくあります。 テナントのコントロールプレーンは、基盤となるコンピュートリソースに直接関連付けられていないため、仮想コントロールプレーン と呼ばれます。
仮想コントロールプレーンは通常、Kubernetes APIサーバー、コントローラーマネージャー、etcdデータストアで構成されます。 これは、テナントのコントロールプレーンとスーパークラスターのコントロールプレーン間の変更を調整するメタデータ同期コントローラーを介してスーパークラスターと対話します。
テナントごとに専用のコントロールプレーンを使用することで、すべてのテナント間で1つのAPIサーバーを共有することによる分離の問題のほとんどが解決されます。 例としては、コントロールプレーンのノイジーネイバー、ポリシーの誤設定による制御不能な影響の波及、WebhookやCRDなどのクラスタースコープオブジェクト間の競合などがあります。 したがって、仮想コントロールプレーンモデルは、各テナントがKubernetes APIサーバーへのアクセスを必要とし、完全なクラスター管理性を期待する場合に特に適しています。
ただし、分離性が改善される一方で、テナントごとに個別の仮想コントロールプレーンを実行・維持するコストがかかります。 さらに、テナントごとのコントロールプレーンは、ノードレベルのノイジーネイバーやセキュリティの脅威など、データプレーンの分離の問題を解決しません。 これらは依然として個別に対処する必要があります。
最終更新 April 04, 2026 at 10:19 AM PST: update (aeec7fa77f)